Breaking: Supertone Supertonic v3 Launches—Compact, On-Device TTS Expands to 31 Languages
San Francisco, CA — Supertone today released Supertonic v3, the third generation of its on-device, ONNX-based text-to-speech system. The new model supports 31 languages, dramatically expands from five, while reducing reading failures and adding expressive tags like <laugh>, <breath>, and <sigh>. At just 99 million parameters, Supertonic v3 is significantly smaller than competing models, enabling fast, memory-efficient inference on CPU.
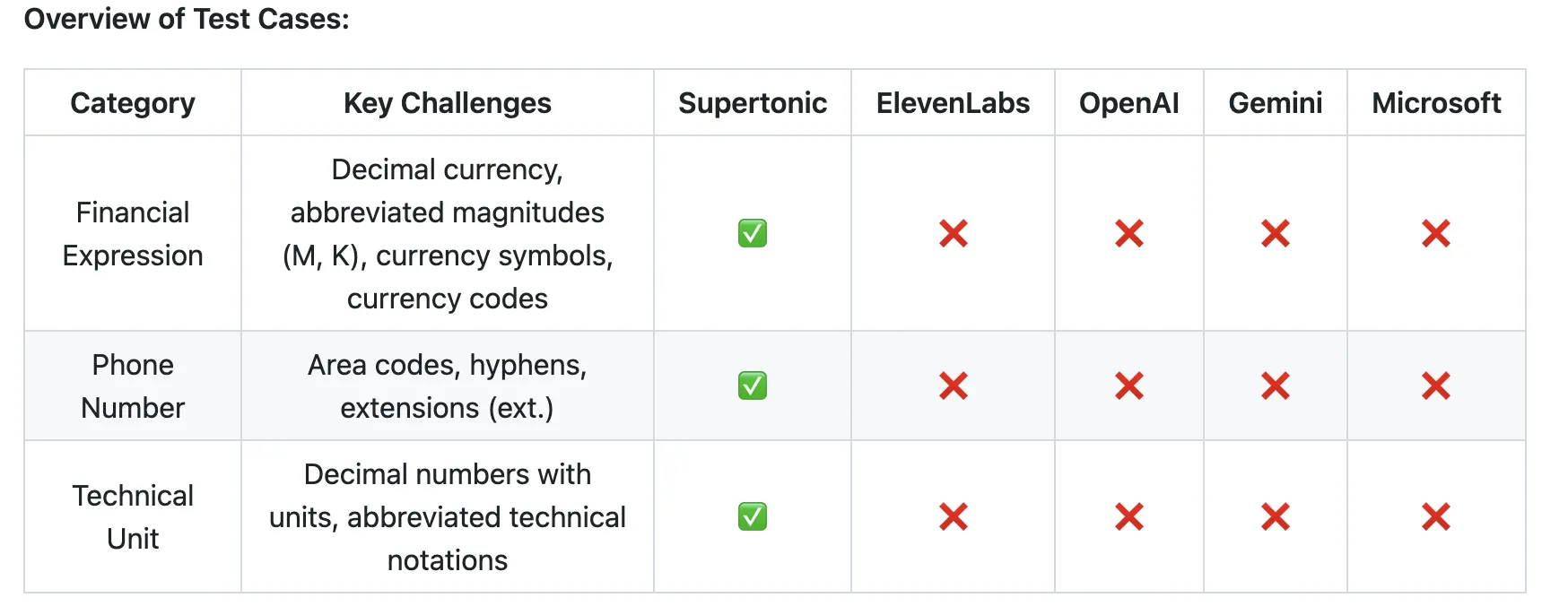
“Supertonic v3 is a leap forward for edge-native TTS,” said Dr. Min-Ji Kim, Supertone’s CTO. “We’ve eliminated repeat and skip failures, maintained speaker similarity across all 31 languages, and for the first time introduced simple prosodic control without a separate model.”
Key Improvements Over v2
Supertonic v3 reduces repeat and skip failures, improves speaker similarity, and expands language coverage from 5 to 31. Version 2 supported English, Korean, Spanish, Portuguese, and French. Version 3 adds Japanese, Arabic, Bulgarian, Czech, Danish, German, Greek, Estonian, Finnish, Croatian, Hungarian, Indonesian, Italian, Lithuanian, Latvian, Dutch, Polish, Romanian, Russian, Slovak, Slovenian, Swedish, Turkish, Ukrainian, and Vietnamese—31 total ISO codes. A special “na” fallback handles unknown text.
Despite the expansion, the model grows only modestly to about 99 million parameters in public ONNX assets—far below the 0.7B–2B parameter range of open TTS systems. The smaller size improves download speed, startup time, and on-device performance. Total disk footprint is 404 MB.
Expressive Tags Enable Inline Prosody
A standout new feature is expressive tag support. Developers can embed tags like <laugh>, <breath>, and <sigh> directly in input text. No separate preprocessing or expressiveness model is needed. “For voice interfaces and accessibility tools, you can now add a breathing pause or laughter inline—simple, powerful,” Kim added.

Background
Supertone’s architecture remains consistent: a speech autoencoder that encodes waveforms into continuous latent representations, a flow-matching-based text-to-latent module, and a duration predictor for natural timing. Flow matching generates audio faster than diffusion models at low step counts—Supertonic v3 produces usable output in just two inference steps.
Version 3 integrates Length-Aware Rotary Position Embedding (LARoPE) for better text-speech alignment and employs Self-Purifying Flow Matching training to handle noisy data labels. These enhancements contribute to the reduction in repeat/skip errors and improved speaker consistency.
The company also recently launched Voice Builder, enabling custom edge-native TTS from user recordings.
What This Means
For developers, Supertonic v3 means a single, small-on-device model that supports a vast language set and provides built-in expressiveness. This reduces latency, eliminates cloud dependency, and simplifies integration. Accessibility tools gain nuanced vocal cues without heavy pipelines.
“We’re making it practical to deploy high-quality TTS on any device, from smartphones to IoT,” Kim said. “Engineers can focus on user experience instead of model optimization.” The small footprint and fast CPU inference open doors for real-time voice assistants, language learning apps, and hands-free navigation. With 31 languages and falling error rates, Supertonic v3 sets a new standard for on-device speech synthesis.